-
This project explores how to make reinforcement learning policies more interpretable by exposing the reasoning behind each action selection. Rather than treating the learned policy as a black box, the system analyzes the value of every available action at each state and identifies both the chosen action and the confidence associated with that decision.
The implementation uses tabular Q-learning in the standard FrozenLake-v1 environment from Gymnasium, with deterministic dynamics (
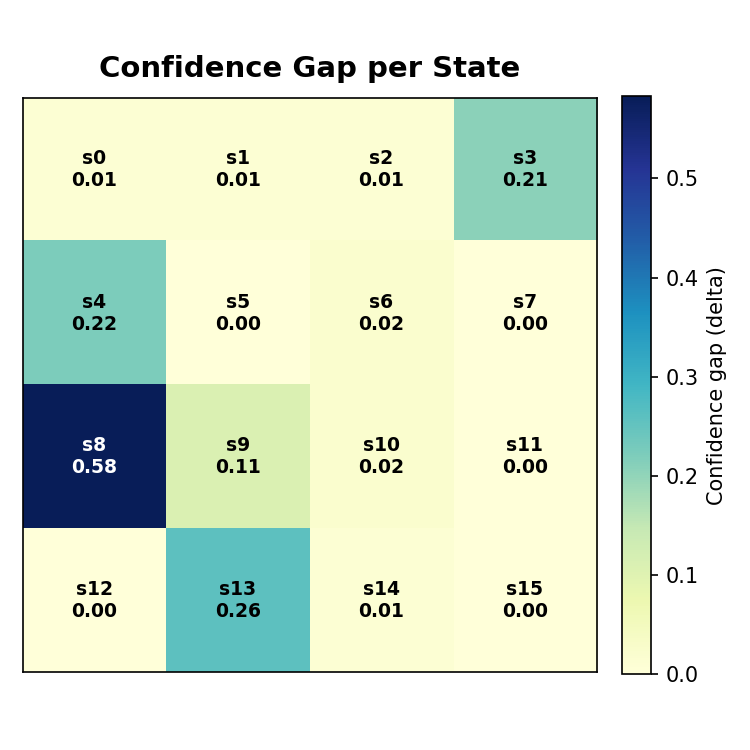
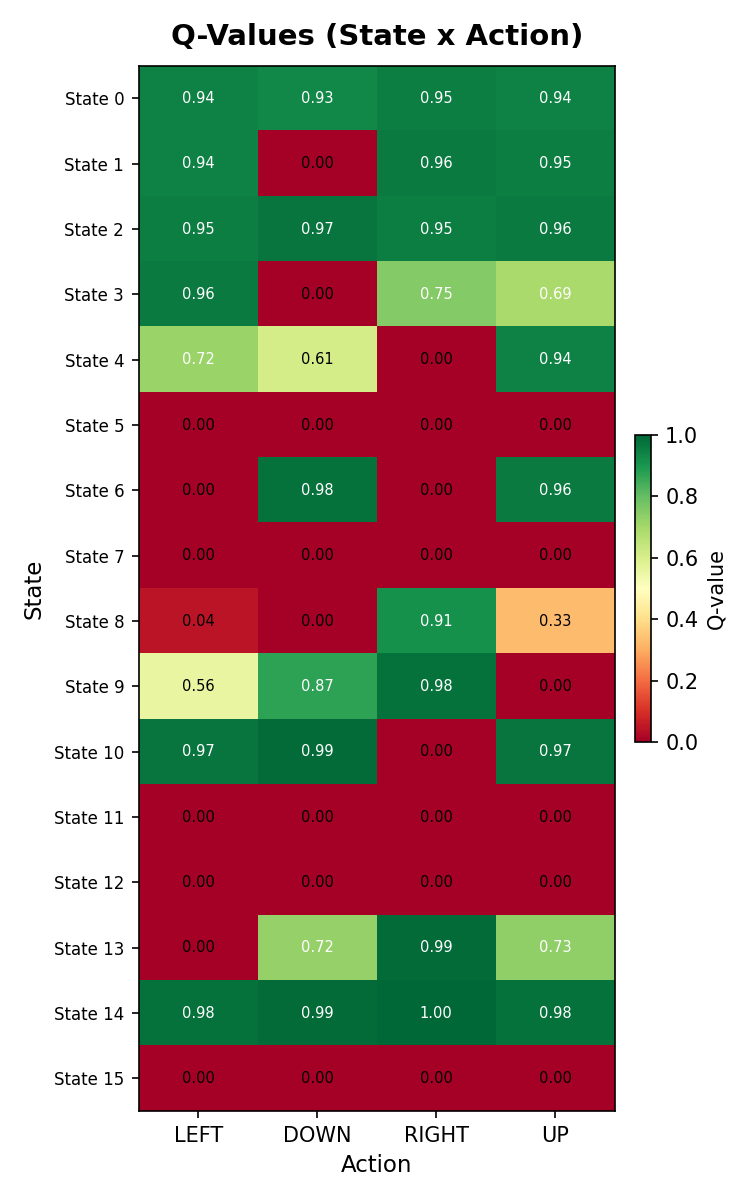
is_slippery=False) to ensure that the learned behavior can be clearly visualized and interpreted. This setting makes it possible to inspect the full state-action structure of the policy.For each state, the project computes the full set of Q-values, ranks the available actions, and measures confidence using the gap between the highest-valued action and the second-best alternative. This provides a simple but effective way to distinguish between states where the agent is decisive and states where its preference is weak or ambiguous.
The project produces three main outputs:
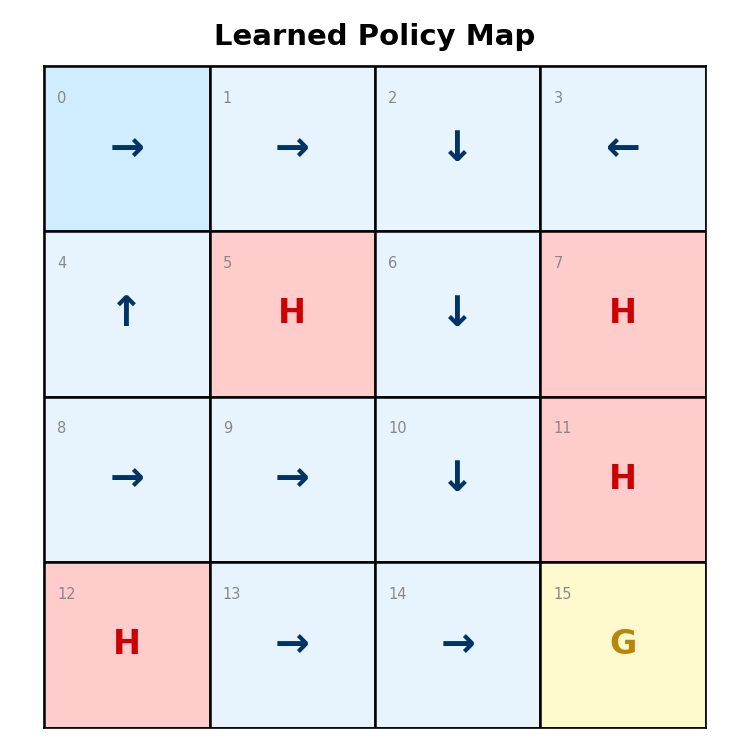
- A policy map showing the selected action in every state
- A confidence map highlighting how strongly the agent prefers its chosen action
- A Q-value heatmap exposing the full decision structure across all state-action pairs
Policy Map
Confidence Map
Q-Value Heatmap
This project demonstrates that even simple RL agents can be made significantly more transparent when their internal action values are surfaced in a structured way. By combining policy visualization with confidence analysis, the project turns a learned controller into a more interpretable decision system.
The full code is available here.